Résumé
Elements de base pour R
Le but de ce tuto est de vous donner les principes de base de R. Il est loin d’être complet mais c’est un très bon guide d’initiation.
Comment installer R ?
Facile !
Il suffit d’aller sur le site et suivre les instructions.
Je vous conseille de télécharger également Rstudio.
et le package Rcmdr depuis la console R.
Voici comment le faire :
Dans la console R, aller à packages→ installer le (s) package(s) → la fenêtre secure CRAN miroir s’ouvre sélectionner votre pays → packages et sélectionner “Rcmdr” . Une fois que c’est fait, testez-le en chargeant ce package dans la console R avec la commande library(Rcmdr)
Vous allez utiliser ce processus chaque fois que vous avez besoin de télécharger une librairie.
Pour utilser un package, il faut toujours le mettre au début de votre script ou dans la console par expemple library(Rcmdr)
OPERATEURS
Il y a 3 types d’opérateurs : arithmétique, de comparaison et de logique.
Voici les symboles utilisés dans R.
Opérateurs arithmétiques
+ Addition
– Soustraction
* Multiplication
/ Division
%/% Division entière
^ Puissance
%% modulo
Opérateurs de comparaison
< Inférieur
> Supérieur
<= Inférieur ou égal
>= Supérieur ou égal
== égal
!= différent
Opérateurs logiques
!x NON logique
x & y ou bien x && y ET logique
x|y ou bien x||y OU logique
xor(x, y) OU exclusif
FONCTIONS DE BASE
Quand vous ouvrez R, une demi-page qui commence par R version 4.2.1 … et se termine par le symbole > et là vous pouvez saisir vos commandes.
Si vous avez le symbole + cela signifie que la commande n’est pas terminée et donc ne peut pas être exécutée.
La réponse de R est indiquée en rouge.
La syntaxe de R est très simple :
Une fonction doit toujours être écrite avec des parenthèses, par exp. mean(c(10,20,30))
Un commentaire doit être précédé par #
[1] indique que l’affichage commence au premier élément.
Le nom d’une variable ou d’une série de données doit obligatoirement commencer par une lettre, il peut y avoir des chiffres par exp. x1, Y2, n3…
Il est à souligner que R distingue, les majuscules des minuscules, donc x et X pourront représenter des variables ou des données complétement différentes.
Pour attribuer une valeur à une variable, utiliser <-
Exemple :
a<-3
b<-4
Si vous tapez a
Vous aurez sa valeur
[1] 3
Si vous voulez faire des opérations par comme l’addition, la multiplication, division… il suffit de taper et vous obtenez le résultat en [1]
a+b
[1] 7
a*b
[1] 12
a/b
[1] 0.75
Vous pouvez mettre les instructions sur la même ligne en les séparant par ;
a+b;a*b; a/b
[1] 7
[1] 12
[1] 0.75
Si vous avez un ensemble de valeurs, vous créez un vecteur pour ensuite effectuer des opérations, par exp
Taille={175,164,170,180,173,168,160}
Poids={70,60,72,75,65,58,54}
Pour R
Taille<-c(175,164,170,180,173,168,160)
Poids<-c(70,60,72,75,65,58,54)
Pour calculer la moyenne par exp. il suffit de :
mean(Taille) ; mean(Poids)
[1] 170
[1] 64.85714
Supposons qu’on veut calculer l’IMC
IMC= Taille^2/Poids
C’est assez intuitif :
IMC<-Taille^2/Poids
> IMC
[1] 437.5 448.3 401.4 432.0 460.4 486.6 474.1
Si vous voulez afficher les données qui sont dans la mémoire, il suffit de taper ls()
ls()
[1] “a” “b” “IMC” “Poids” “Taille”
Si vous voulez les détails, utilisez ls.str(pat=””)
Par exemple :
ls.str(pat=”IMC”)
IMC : num [1:7] 438 448 401 432 460 …
ls.str(pat=”Taille”)
Taille : num [1:7] 175 164 170 180 173 168 160
Pour effacer des données de la mémoire, utilisez la fonction :
rm(nom de la variable) pour 1 seule variable, par exp.
rm(a)
rm(a)
> a
Erreur : objet ‘a’ introuvable, effectivement a est bien effacé
rm(x, y) pour effacer 2 variables x et y
rm(list=ls()) pour effacer tous les données en mémoire
rm(list=ls(pat= “^nom de la variable”)) pour sélectionner les données à effacer
Exemple
rm(list=ls(pat= “^Taille”))
> Taille
Erreur : objet ‘Taille’ introuvable
Si vous cherchez de l’aide pour une fonction, il suffit de taper dans la console : ? le nom de la fonction. La recherche se fait dans la documentation de R . Par exp :
> ?ls
starting httpd help server … done
Evidemment, vous pouvez lancer une recherche sur le net.
Quelques fonctions pour calculer les probabilités avec des lois de distribution
Normale : pnorm(x, mean=, sd=)
#Calculer P(x≤120) pour X~ N(100,152)
pnorm(120, mean=100, sd=15)
[1] 0.9087888
Exponentielle : pexp(x, rate=)
#Calculer P(x≥7) pour X~ε(λ=1/7)
1-pexp(7, 1/7)
[1] 0.3678794
Poisson : ppois(x, lambda)
#Calculer P(x≤5) pour X~P(3)
ppois(5, 3)
[1] 0.9160821
Student : pt(x, df)
#Calculer P(X≤1.2) pour X~t(15)
pt(1.2,df=15)
Pearson (chi-2): pchisq(n, df)
#Calculer P(X≥22.3) pour X~ch-2(15)
1-pchisq(22.3, 15)
#ou
pchisq(22.3, 15,lower.tail = F)
[1] 0.1001756
Binomial: pbinom(x, size, prob)
#Calculer P(x≤6) pour X~B(n=25,P=0.25)
pbinom(6, 25, 0.25)
[1] 0.5610981
Hypergéométrique: phyper(x, m, n, k)
Avec
x : représente l’ensemble de données de valeurs
m : taille de la population
n : nombre d’échantillons prélevés
k : nombre d’éléments de caractéristique dans la population
#Calculer P(x≤3)
phyper(3, 19,11, 5)
[1] 0.619216
binomiale negative: pnbinom(n, size, prob)
#Calculer P(X≤100) pour X∼ BN(r=10; p=0.08)
pnbinom(100, 10, 0.08)
[1] 0.385063
uniforme: punif(x, min=, max=)
#Calculer P(X≤115) pour X∼ U(min=100,max=135)
punif(115, min=100,max=135)
[1] 0.4285714
Notez bien que ces fonctions donnent par défaut les probabilités à gauche c.-à-d. P(x≤a) ce qui fait pour calculer P(x≥a) il faut faire 1- P(x≤a) ou ajouter l’option à la fonction lower.tail = F
Pour calculer la densité de probabilité, remplacer la lettre p par d.
Exemples
#Calculer P(X=100) pour X∼ BN(r=10; p=0.08)
dnbinom(100, 10, 0.08)
[1] 0.01095067
#Calculer P(x=5) pour X~P(3)
dpois(5, 3)
[1] 0.1008188
#Calculer P(x=6) pour X~B(n=25,P=0.25)
dbinom(6, 25, 0.25)
[1] 0.1828195
Pour déterminer le seuil qui correspond à une probabilité, remplacer la lettre p par q
Exemples
#Calculer a tel que P(x≤a)= 0.9088 pour X~ N(100,152)
qnorm(0.9088,mean=100,sd=15)
[1] 120.001. Rappelez-vous qu’on avait trouvé pour P(x≤120) =0.9088
#Calculer b tel que P(x≤b)=0.91 pour X~P(3)
qpois(0.91,3)
[1] 5.
Données
Plusieurs façons existent pour manipuler les données dans R, on va voir les plus simples.
On a déjà utilisé la fonction c pour créer un vecteur pour une petite série de donnée.
On reprend l’exemple :
Taille<-c(175,164,170,180,173,168,160)
Pour importer des données stockées dans un fichier Excel, vous avez plusieurs fonctions, on va donner les détails de celles qu’on utilise dans les modules.
read_excel
D’abord, assurez-vous que votre fichier est sous le bon format xlsx. Voici comment l’importer depuis votre ordinateur.
Indiquer le chemin où se trouve votre fichier. Pour le savoir, click droit→ propriété
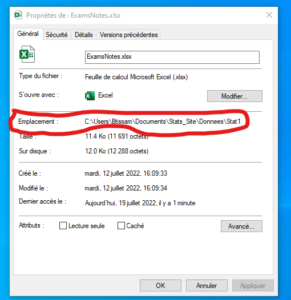
Nommer votre jeu de donnée
Mesdonnees<- read_excel (“/Users/Btissam/Documents/Stats_Site/Donnees/Stat1/ExamsNotes.xlsx”,”Exa_Final”)
read.csv()
Assurez-vous que votre fichier est sous le bon format csv.
Mesdonnees<- read.csv(“/Users/Btissam/Documents/Stats_Site/Donnees/Stat1/ExamsNotes.cv”,”Exa_Final”)
Pour toute analyse des données, utiliser le nom que vs avez attribué à votre jeu de données. Ici Mesdonnees
Pour les paramètres de position, moyenne, médiane , quartile. Vous pouvez utiliser des fonctions pour chaque paramètre par exp. mean(Mesdonnees) donne la moyenne. Mais
La fonction summary(Mesdonnees) donne tous ces paramètres de position.
La fonction sd() donne l’écart-type.
Pour créer un tableau de données, une des fonctions est : data.frame(x,y) ou x, y sont des vecteurs de même longueur, vous pouvez avoir plus que 2 vecteurs.
Exemple :
On veut créer un tableau ou l’IMC correspond à la taille et le poids
Taille<-c(175,164,170,180,173,168,160)
Poids<-c(70,60,72,75,65,58,54)
IMC<- c(437.5 448.3 401.4 432.0 460.4 486.6 474.1)
data.frame(Taille,Poids,IMC)
Taille Poids IMC
1 175 70 437.5
2 164 60 448.3
3 170 72 401.4
4 180 75 432.0
5 173 65 460.4
6 168 58 486.6
7 160 54 474.1
Pour créer une matrice, une des fonctions est:
matrix(data =, nrow = , ncol = , byrow = FALSE, dimnames = NULL
byrow: option qui précise que les valeurs données par data doivent remplir successivement les colonnes (le défaut) ou les lignes (si TRUE).
dimnames permet de donner des noms aux lignes et colonnes
Exemple
Créer les matrices suivantes en nommant les lignes et Colonnes
A B C
M 35 10 65
Mat1 = P 25 75 82
S 3 12 8
A B C
M 15 10 6
Mat2 = P 5 7 2
S 30 12 80
Script R
### Création de matrices
Nomligne <-c(“M”,”P”,”S”)
Nomcol <-c(“A”,”B”,”C”)
Mat1 <- matrix(c(35,10,65, 25,75,82, 3,12,8),nrow=3,ncol = 3,
byrow=TRUE,
dimnames = list(Nomligne,Nomcol))
Mat1
Mat2<- matrix(c(15,10,6, 5,7,2, 30,12,80),nrow=3,ncol = 3,
byrow=TRUE,dimnames = list(Nomligne,Nomcol))
Mat2
Faire la somme des 2 matrices
### somme matricielle
SommeMat<-Mat1+Mat2
SommeMat
> SommeMat
A B C
M 50 20 71
P 30 82 84
S 33 24 88
Multiplier Mat1*Mat2
Attention respecter l’ordre,
Mat1*Mat2≠ Mat2* Mat1
### Produit matriciel,
MultiMat<-Mat1%*%Mat2
MultiMat
> MultiMat
A B C
M 2525 1200 5430
P 3210 1759 6860
S 345 210 682
Les valeurs manquantes sont représentées par NA
(Not Available).
les valeurs infinies ±∞ sont représentées Inf et −Inf et celles qui ne sont pas des nombres par NaN (Not a Number) .
Une très grande ou très petite valeur numérique peut-être représentée par une notation exposant ou à la puissance ±n (e+n ou e-n) :
Par exp. X<- 1.5*10^12
X
[1] 1.5e+12
Y<- 2.3*10^-6
Y
[1] 2.3e-06
Pour générer des données régulières :
Une façon très simple est :
X<- a:b
avec a : valeur minimale et b : valeur maximale.
Exemple :
X<-10 :20
C’est une série de 10,11, 12…20 , un pas de 1
Si on veut un pas différent de 1, utiliser la fonction :
seq(a,b,p) où a et b restent des valeurs min. et max et p le pas.
On reprend l’exemple précédant avec un pas de 2
Y<- seq(10,20,2)
[1] 10 12 14 16 18 20
Pour générer une série régulière avec k niveaux et n répétitions, utiliser la fonction
gl(k,n)
Exemple gl(5,3) : 5 niveaux avec 3 répétitions
gl(5,3)
[1] 1 1 1 2 2 2 3 3 3 4 4 4 5 5 5
Levels: 1 2 3 4 5
Pour générer des données aléatoires, il est pratique d’utiliser les fonctions de loi de probabilités sous forme
rfunc(n,p1,p2, . . .) où func est la loi de probabilité, n le nombre de données à générer et p1, p2, . . ., les paramètres propres à la loi. Revenez vers les fonctions déjà vues pour le calcul de probabilité avec des lois de probabilité en remplaçant p par r.
Exemples
rnorm(25, 0,1) génère 25 données aléatoires selon la loi normale centrée réduite Z(0,1)
[1] -0.15806439 -1.44140675 0.81439699 1.36831073 -1.50009096 0.31995202 0.46803333 2.12871797 -0.38734316
[10] 0.82927372 0.79663089 -0.35690471 -0.35653676 0.53620846 0.06212313 -1.14206442 0.37483228 -0.81710345
[19] -0.12017081 -1.19793800 0.79654906 -0.73273546 0.33337356 -0.08279554 0.90869115
rt(20, 4) génère 20 données aléatoires selon la loi Student avec un df de 4.
[1] 0.94411178 -0.08435705 0.26831883 5.92206782 0.64113283 -0.11801267 0.61679028 -1.00470992 0.72792033
[10] -0.07706505 1.28537935 -1.74865798 -1.42324071 -0.65494584 -2.51700444
Les graphiques
Vous aurez souvent besoin de représenter vos données par des graphiques, cette section reste dans l’esprit de ce tuto, Donc, on va s’intéresser aux fonctions les plus utilisées en statistique dans nos modules.
Les fonctions principales pour un graphes
plot(x) : tracer une série de valeurs
plot(x,y) : tracer y en fonction de x
boxplot(x) : tracer une boite à moustaches
hist(x) : tracer un histogramme
barplot(x) : tracer un graphe avec des barres
qqnorm(x) : quantiles de x en fonction des valeurs attendues selon une loi normale
qqplot(x,y) : quantiles de y en fonction de ceux de x
Toutes ces fonctions ont plusieurs options qui peuvent être utile à commenter et comprendre un graphe comme legend, title, text.
Il y a aussi des fonctions secondaires qui vont avoir une action sur un graphe existant par exemple ajouter des points, des lignes, une autre fonction…
Points(x, y) : ajoute des points
lines(x, y) : ajoute des lignes
segments(x0, y0,x1, y1) : ajoute des segments des points (x0,y0) aux points (x1,y1)
arrows(x0, y0,x1, y1, angle=30,code=2) : ajoute des flèches aux points (x0,y0) si code=2, aux points(x1,y1) si code=1, ou aux deux si code=3 ; l’option angle contrôle l’angle de la pointe par rapport à l’axe
abline(a,b) : ajoute une ligne de pente b et a ordonné à l’origine.
abline(x,y) : ajoute une fonction
abline(h=y) : ajoute une ligne horizontale sur l’ordonnée y
abline(v=x) : ajoute une ligne verticale sur l’ordonnée x
Cette liste est loin d’être exhaustive mais c’est suffisant pour débuter, vous allez l’étoffer au fur et à mesure de vos besoins.
Il est à noter que vous pouvez ajouter des expressions mathématiques sur un graphe avec la fonction text et expression qui permet de transformer son argument à une équation mathématique
Exemple :
text(x, y, expression(p == over(1, 1+e^-(beta*x+alpha))))
Exemple
On reprend l’exemple du calcul de l’IMC pour 7 individus.
| Individu | Taille | Poids |
| 1 | 175 | 70 |
| 2 | 164 | 60 |
| 3 | 170 | 72 |
| 4 | 180 | 75 |
| 5 | 173 | 65 |
| 6 | 168 | 58 |
| 7 | 160 | 54 |
Répondre aux questions en utilsant un script R
- Créer un tableau où l’IMC correspond à la taille et le poids de chaque individu. IMC=Taille^2/Poids, arrondir à 1 digit.
- Calculer tous les paramètres de position et de dispersion (ecart-type) pour la taille, le poids et l’IMC.
- Tracer les courbes représentant la taille, le poids et l’IMC
Réponse
Voici le script à télécharger : Exemple_TutoR.txt
Plus pratique de l’exécuter avec Rstudio mais d’abord recopiez le dans un nouveau R script et ensuite exécutez-le