Réponse 1
1) importer les données
On attribue le nom ventes au fichier pour faciliter la lecture du code.
Vous pouvez utiliser un autre nom si vous le souhaitez.
ventes <- read.csv(« chemin/vers/le/fichier/donnees-ventes-exercice-r-debutant.csv »)
2) Affichez les premières lignes du tableau
head(ventes)
3) charger dplyr
Il faut que dplyr soit déjà installer, ensuite :
library(dplyr)
4) calculer le chiffre d’affaires
On crée une nouvelle variable :
chiffre_affaires <- ventes$prix * ventes$quantite
chiffre_affaires
5) Ajouter chiffre d’affaires dans une nouvelle colonne
On crée une nouvelle variable :
ventes$chiffre_affaires <- ventes$prix * ventes$quantite
head(ventes)
6) calculer le chiffre d’affaires total
On obtient le total des ventes :
sum(ventes$chiffre_affaires)
7) filtrer la région Nord
On sélectionne uniquement les ventes du Nord.
ventes %>% filter(region == « Nord »)
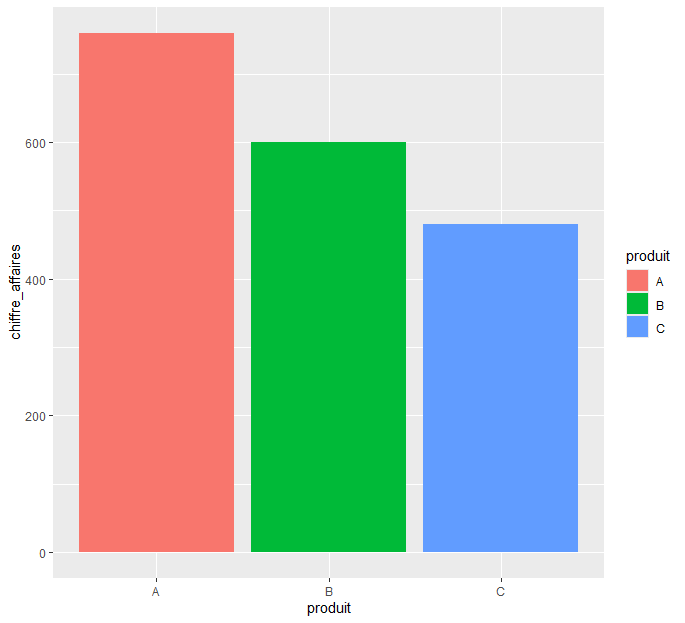
8) graphique du chiffre d’affaires par produit
ggplot(ventes, aes(x = produit, y = chiffre_affaires)) +
geom_bar(stat = « identity ») +
labs(title = « Chiffre d’affaires par produit »,
x = « Produit »,
y = « Chiffre d’affaires »)
Réponse 2
On attribue le nom ventes.region au fichier pour faciliter la lecture du code.
Vous pouvez utiliser un autre nom si vous le souhaitez.
1)créer le chiffre d’affaires
La fonction mutate() permet d’ajouter une nouvelle colonne.
ventes.region <- ventes.region %>%
mutate(chiffre_affaires = prix * quantite)
2) chiffre d’affaires total par région
On regroupe les données par région avec la fonction group_by ()
ventes.region %>%
group_by(region) %>%
summarise(total_CA = sum(chiffre_affaires))
3)chiffre d’affaires moyen par produit
On regroupe les données par produit avec la fonction group_by ()
ventes.region %>%
group_by(produit) %>%
summarise(moyenne_CA = mean(chiffre_affaires))
4)région avec le CA le plus élevé
On regroupe les données par région avec la fonction group_by ()
On calcule la somme du CA et on trie par ordre décroissant avec la fonction arrange()
La première ligne = meilleure région.
ventes.region %>%
group_by(region) %>%
summarise(total_CA = sum(chiffre_affaires)) %>%
arrange(desc(total_CA))
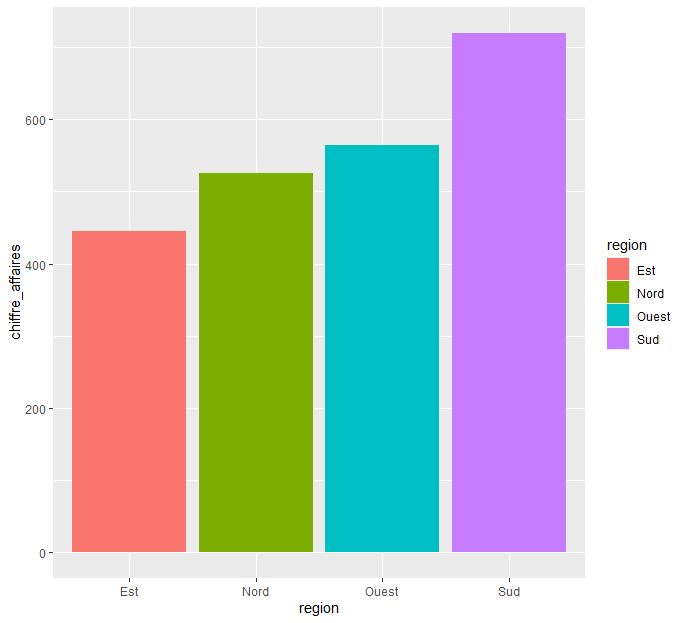
Sud 720← meilleure région.
Ouest 565
Nord 525
Est 445
5) filtrer les ventes > 100
On utilise la fonction filter()
ventes.region %>%
filter(chiffre_affaires > 100)
Voici le résultat
| id | produit | prix | quantite | region | categorie | chiffre_affaires |
| 10 | A | 20 | 6 | Sud | Standard | 120 |
| 14 | B | 15 | 7 | Sud | Promo | 105 |
| 22 | A | 20 | 6 | Sud | Standard | 120 |
| 30 | C | 30 | 4 | Sud | Premium | 120 |
6) Graphique CA par région
7)Interprétation
La région Sud est la plus performante en termes de chiffre d’affaires, tandis que la région Est est la moins performante.
L’analyse par région permet de mieux comprendre les différences de ventes.
Ces différences peuvent s’expliquer par :
- une demande plus forte dans certaines régions
- une meilleure stratégie commerciale
- ou une concentration des ventes
Il est donc important d’analyser les données par région plutôt que de se limiter à un total global.