Si vous avez suivi un cours de statistiques, vous avez probablement déjà croisé cette célèbre courbe en cloche appelée loi normale, ou distribution gaussienne.
Mais derrière cette formule se cache une idée beaucoup plus simple : comprendre comment se répartissent naturellement certaines données comme les tailles, les erreurs de mesure, les notes ou encore certains phénomènes économiques.
Dans cet article, nous allons voir simplement :
- ce qu’est la loi normale,
- pourquoi elle apparaît si souvent en statistiques ?
- ce qu’elle représente concrètement,
- et comment son histoire permet de mieux comprendre son utilité.
Parce qu’avant la formule, il y a une histoire. Et cette histoire explique tout.
🎥 Une explication vidéo de la loi normale est également disponible sur ma chaîne YouTube A Moi Les Stats.
L’histoire : Pourquoi la loi normale apparaît-elle partout ?
Abraham de Moivre — le joueur qui cherchait des patterns (1733)
Tout commence avec un mathématicien français exilé en Angleterre, Abraham de Moivre.
En 1733, de Moivre travaille sur un problème qui passionne les esprits de l’époque : les jeux de hasard. Plus précisément, il cherche à calculer la probabilité d’obtenir exactement un certain nombre de pile en lançant une pièce de monnaie un grand nombre de fois.
C’est un problème de loi binomiale — mais les calculs deviennent rapidement ingérables quand le nombre de lancers augmente. Imagine calculer à la main la probabilité d’obtenir exactement 47 pile sur 100 lancers. Possible. Mais 4 700 pile sur 10 000 lancers ? Cauchemardesque.
De Moivre remarque quelque chose d’extraordinaire : quand le nombre d’essais devient très grand, la distribution binomiale prend la forme d’une courbe lisse et symétrique. Il développe une formule d’approximation — sans le savoir, il vient de poser les premières pierres de la loi normale.
Pierre-Simon Laplace — le pont entre probabilité et réalité (1778)
Quelques décennies plus tard, le mathématicien français Pierre-Simon Laplace va beaucoup plus loin.
Laplace s’intéresse à un problème fondamental : comment combiner des mesures imparfaites pour obtenir la meilleure estimation possible d’une réalité ? Les astronomes de l’époque mesurent la position des étoiles — mais chaque mesure contient des erreurs.
Laplace démontre que lorsqu’on additionne un grand nombre d’erreurs aléatoires indépendantes — quelle que soit leur distribution d’origine — le résultat converge toujours vers la même forme de courbe.
Ce résultat fondamental s’appellera plus tard le Théorème Central Limite. Et la courbe vers laquelle tout converge ? C’est la loi normale. Laplace comprend que cette loi n’est pas qu’un outil de calcul. C’est une propriété profonde de la nature.
Carl Friedrich Gauss — l’astronome qui lui donne son nom (1809)
C’est Carl Friedrich Gauss, mathématicien allemand surnommé « le prince des mathématiques », qui va formaliser et populariser cette distribution.
Gauss travaille sur les erreurs de mesure en astronomie. Il développe la méthode des moindres carrés et démontre que si les erreurs suivent cette fameuse courbe en cloche, sa méthode donne la meilleure estimation possible.
Il publie ses travaux en 1809 dans Theoria Motus Corporum Coelestium — la théorie du mouvement des corps célestes.
La distribution prendra son nom : la gaussienne ou courbe de Gauss. Même si de Moivre et Laplace l’avaient précédé, c’est Gauss qui l’ancre définitivement dans les outils mathématiques modernes.

Le sens : ce que la loi normale représente vraiment
Pourquoi les tailles suivent une loi normale?
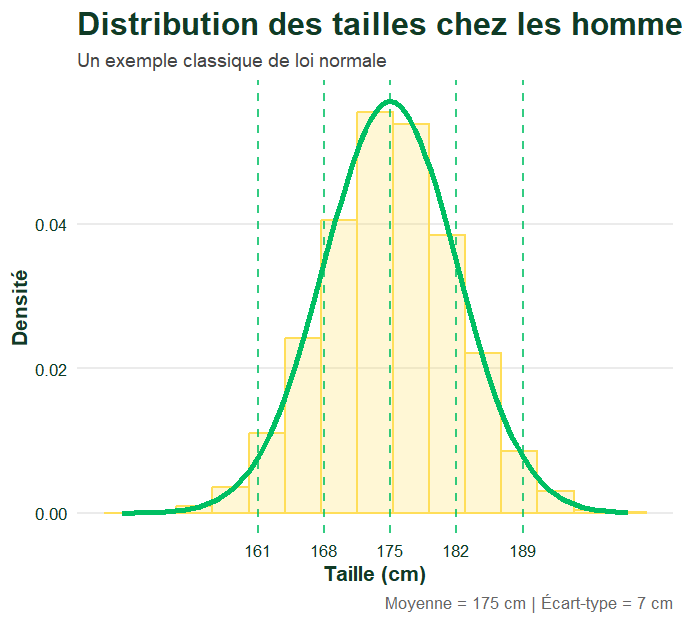
Imaginez que vous mesurez la taille de 10 000 adultes français pris au hasard. Vous obtenez des valeurs qui vont de 1m50 à 1m95, avec une concentration autour de 1m75.
Si vous tracez l’histogramme de ces mesures, vous obtenez une forme caractéristique : beaucoup de personnes autour de la valeur moyenne, de moins en moins au fur et à mesure qu’on s’en éloigne, de façon symétrique des deux côtés. C’est exactement la forme d’une courbe en cloche.
La taille d’un individu est influencée par des centaines de facteurs indépendants : des dizaines de gènes différents, l’alimentation, le sommeil, les hormones de croissance. Chacun contribue un petit peu — positivement ou négativement — à la taille finale. Et quand on additionne un grand nombre de petites influences indépendantes, le résultat suit une loi normale. Ce n’est pas une coïncidence — c’est la conséquence mathématique inévitable du Théorème Central Limite.
La formule: ce qu’elle dit en langage naturel
La loi normale est caractérisée par deux paramètres :
→ La moyenne μ (mu) — c’est le centre de la courbe, la valeur autour de laquelle les données se concentrent. Pour les tailles, c’est environ 1m75 chez les hommes français.
→ L’écart-type σ (sigma): c’est ce qui mesure l’étalement de la courbe. Un écart-type petit signifie que les valeurs sont très concentrées autour de la moyenne.
En langage naturel, la formule répond à cette question : « Pour une valeur donnée x, quelle est la densité de probabilité autour de ce point ? » Concrètement : les individus de 1m75 sont très fréquents, ceux de 1m90 sont moins fréquents, ceux de 2m10 sont rarissimes.
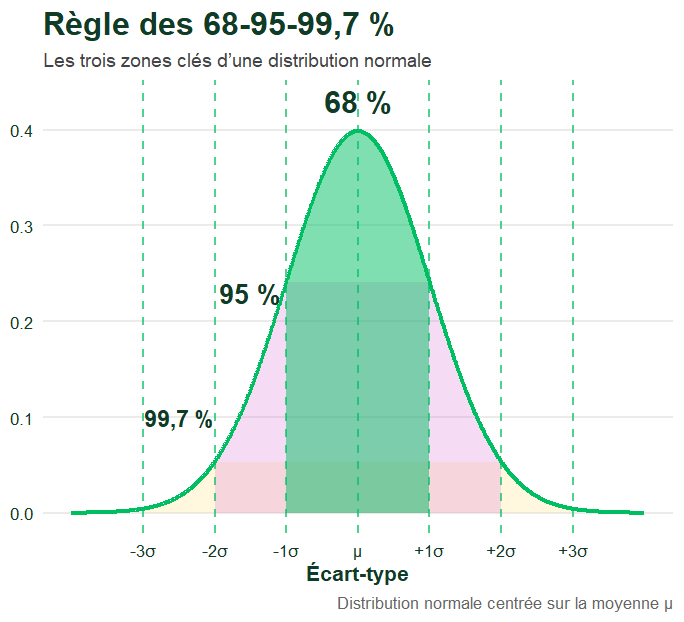
La règle des 68-95-99,7 %
📐 Règle empirique fondamentale Dans toute distribution normale :
→ 68 % des valeurs se trouvent à moins d’un écart-type de la moyenne (±1σ)
→ 95 % des valeurs se trouvent à moins de deux écarts-types (±2σ)
→ 99,7 % des valeurs se trouvent à moins de trois écarts-types (±3σ)
Pour les tailles avec une moyenne de 1m75 et un écart-type de 7 cm :
→ 68 % des hommes mesurent entre 1m68 et 1m82
→ 95 % mesurent entre 1m61 et 1m89
→ 99,7 % mesurent entre 1m54 et 1m96
Cette règle te permet de raisonner sur n’importe quelle distribution normale sans même ouvrir une table statistique.
Quand utiliser la loi normale, et quand ne pas l’utiliser