Réponse 1
1.Identifier les variables X et Y
On cherche à savoir si la note dépend, donc c’est la variable Y dépendante ; nombre de heures de sommeil , X : Variable indépendante.
2. Calculer le coefficient de corrélation
coefficient de corrélation≈0.903. Ce coefficient indique une forte corrélation positive entre le nombre d’heure de sommeil et la note obtenue à l’examen .
3.Déterminer l’équation de la droite d’ajustement
L’équation de la droite est de la forme :
Y(Note) = b0 + b1x( HeuresSommeil)
où b0 est l’ordonnée à l’origine (intercept), et b1 le coefficient de régression (pente). voir le output du test
y=22.404+6.889x
Pour une visualisation du modèle, vous pouvez tracer le nuage de points (les observations) ainsi que la droite de régression (l’estimation) à l’aide d’un graphique.
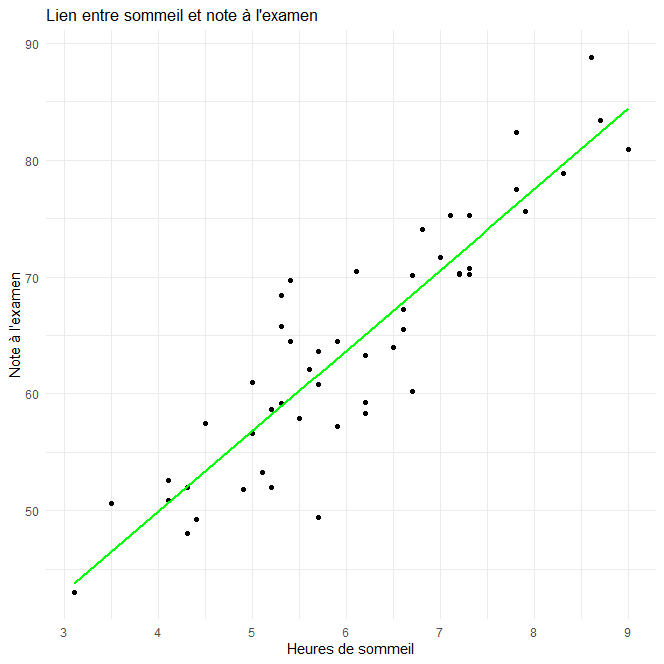
4.Le modèle est-il satisfaisant ?
Il faut vérifier la valeur du coefficient de détermination R² dans le résumé du modèle :R²=0.8134≈0,81
Le modèle d’ajustement est très satisfaisant car il explique env. 81% la variabilité de la note en fonction des heures de sommeil . Autrement dit, la note dépend à 81% des heures de sommeil.
5. Hypothèses du test sur le lien linéaire entre X et Y
Formuler les hypothèses pour mettre en évidence une relation linéaire positive entre x et y
H0 : ρ = 0 (Il n’y a pas de relation linéaire entre les deux variables)
H1 : ρ > 0 (Il existe une relation linéaire positive significative)
6.Statistique de test et p-value
Dans le résumé du modèle :
t= 14.464
p-value= 2e-16≈0
7. Région de rejet
RC =[tα,ddl=0.05 ,48 ; +∞[=[1.68 , +∞[
8.Conclusion du test
Comme t est à l’intérieure de RC ou p-value < 0,05, on rejette H₀ , donc, Il existe une relation linéaire positive significative entre les heures de sommeil et la note.
9. Variation de la note pour 1 heure de sommeil supplémentaire
b1, la pente de la droite qui représente l’augmentation moyenne de la note par heure de sommeil en plus.
Donc, chaque heure de sommeil supplémentaire augmente la note de 6,889 points en moyenne.
10. Note attendue pour un étudiant ayant dormi 8 heures
Vous pouvez effectuer le calcul manuellement, mais il est plus pratique d’utiliser la fonction predict
À noter : si vous travaillez avec Rcmdr, cette fonction n’est pas directement disponible. Il faudra donc passer par RScript
Pour un étudiant ayant dormi 8 heures, il pourrait obtenir une note de 77.518
11.Déterminer un intervalle de prédiction pour la note estimée à la question 10
IP=[68.0623, 86.974]
À partir du modèle de régression linéaire établi, nous avons estimé la note d’un étudiant ayant dormi 8 heures la veille de l’examen. La valeur prédite est accompagnée d’un intervalle de prédiction à 95 %, qui reflète l’incertitude autour de cette estimation individuelle.
Ainsi, un étudiant ayant dormi 8 heures aurait une note attendue comprise entre 68.06 et 86.97.
Cet intervalle tient compte de la variabilité des performances individuelles et montre qu’à nombre d’heures de sommeil égal, la note peut varier considérablement d’un étudiant à l’autre.
Out put du test
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 22.4036 2.9530 7.587 9.33e-10 ***
HeuresSommeil 6.8893 0.4763 14.464 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 4.565 on 48 degrees of freedom
Multiple R-squared: 0.8134, Adjusted R-squared: 0.8095
F-statistic: 209.2 on 1 and 48 DF, p-value: < 2.2e-16
Réponse 2
1.Nature de la corrélation entre le nombre de jours d’absence et la productivité
D’abord on définit les variables: On cherche à expliquer ou prédire et la productivité (y) par le nombre de jours d’absence (x).On vérifie s’il y a une corrélation entre ces variables par un test de corrélation qui a donnée r= -0.97
Donc c’est une corrélation négative, ce qui signifie qu’une absence plus longue entraînerait une baisse de productivité.
2.Prédiction
Si un employé est absent pendant 10 jours, sa productivité prédite par le modèle de régression est la suivante :
La droite de régression utilisée pour faire la prédiction est :
y = 289.1 – 7.8 x
Pour une visualisation du modèle, vous pouvez tracer le nuage de points (les observations) ainsi que la droite de régression (l’estimation) à l’aide d’un graphique.
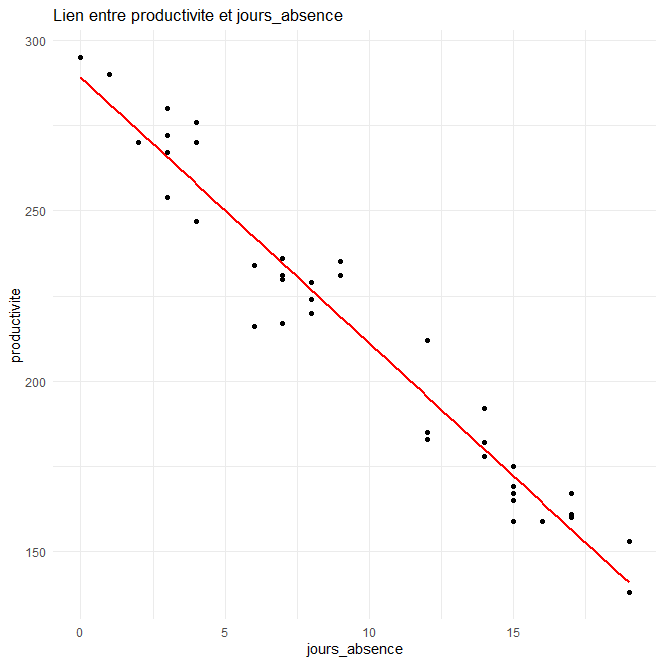
En utilisant la fonction predict avec x = 10, on obtient une estimation de 211.
Cela signifie que, selon le modèle, un employé ayant 10 jours d’absence traiterait en moyenne environ 211 commandes au cours du mois. Cette estimation est cohérente avec la corrélation négative observée : plus le nombre de jours d’absence augmente, plus la productivité diminue.
Intervalle de prédiction :
[189.86 ; 232.33]
L’intervalle de prédiction à 95 % reflète l’incertitude autour de cette estimation individuelle. Autrement dit, si un employé s’absente 10 jours, le nombre de commandes qu’il est susceptible de traiter se situera entre 189.86 et 232.33 dans 95 % des cas.
Cet intervalle prend en compte la variabilité entre les individus et montre que, même avec le même nombre de jours d’absence, la productivité peut varier sensiblement d’un employé à l’autre.
3.Prédiction au-delà de la plage de données
Si l’on essaie de prédire la productivité pour un employé absent 30 jours, on extrapole au-delà de la plage de données observées de 0 à 19 jours d’absence.
Le modèle prédit alors une productivité d’environ 55 commandes. Bien que ce chiffre soit encore positif, il se rapproche dangereusement de zéro, et une extrapolation plus lointaine pourrait même aboutir à une valeur négative, ce qui n’a aucun sens en pratique.
Cela montre que le modèle linéaire n’est pas fiable en dehors de la plage des données observées. Une telle prédiction pourrait donc être trompeuse, car le comportement de la productivité au-delà de 19 jours d’absence pourrait ne plus suivre une relation linéaire.
4.Intérprétation de l’ordonnée à l’origine (Intercept)
L’ordonnée à l’origine (Intercept = 289.0984 ) représente la productivité prédite lorsque les jours d’absence sont à zéro, donc pour un employé qui n’a pris aucun jour d’absence(x=0).
Ce chiffre est interprétable dans le contexte de l’entreprise : il correspond à la productivité maximale estimée, soit environ 289 commandes par mois, pour un employé présent tous les jours. Cette valeur reste cohérente avec les données observées, puisque le maximum relevé dans l’échantillon est de 295 commandes.
Out put du test
Call:
lm(formula = productivite ~ jours_absence, data = Ex2_productivite)
Residuals:
Min 1Q Median 3Q Max
-26.2963 -6.7951 -0.2955 6.9024 18.1030
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 289.0984 3.3691 85.81 <2e-16 ***
jours_absence -7.8003 0.2974 -26.23 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 10.36 on 38 degrees of freedom
Multiple R-squared: 0.9477, Adjusted R-squared: 0.9463
F-statistic: 688 on 1 and 38 DF, p-value: < 2.2e-16
Réponse 3
1.Prédiction
D’abord on définit les variables: On cherche à expliquer ou prédire la consommation d’électricité (y) par la température extérieure(x).
On va utiliser le modèle de la régression linéaire:
y= 151.195-3x
la pente de la droite est négative ce qui signifie qu’il y a une corrélation négative: une température élevée entraînerait une baisse de consommation d’électricité comme le montre le graphique suivant.
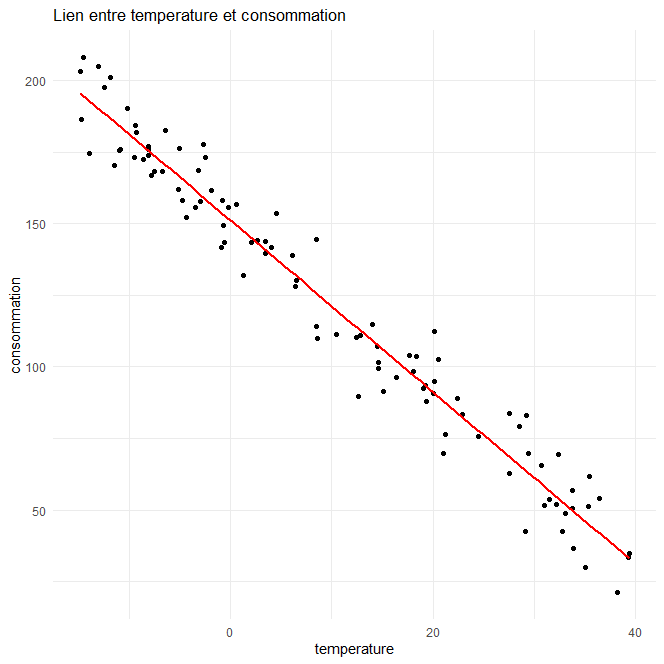
et on utilise la droite de régression pour faire une prédiction.
y= 151.195-3x=151.195-3*25 =
= 76.22173≈76.22
mais c’est plus pratique d’ ajouter ce code dans la console R si vs utlisez Rcmdr modele3 doit correspondre au modèle dans output de la Régression
predict(modele3 , newdata = data.frame(temperature= 25))
1
76.22
2.la température augmente d’une unité (1 degré) , de combien la consommation d’électricité diminue ou augmente?
Si la température augmente d’une unité (1 degré) , la consommation d’électricité diminue d’environ de 3 unités.
Cette information est utile pour anticiper les besoins en énergie et ainsi planifier la production de manière optimale.
3.Prédiction au-delà de la plage de données
À une température de -18°C, l’estimation de la consommation d’électricité est de 205.18.
round(predict(modele3 , newdata = data.frame(temperature= -18)),2)
Cette prédiction pourrait ne pas être fiable, car -18 est en dehors de la plage de la régression linéaire.
4.Fiabilité du modèle
Le modèle peut toujours êre fiable tant qu’on reste dans la plage . Il est donc prudent d’éviter d’extrapoler hors de la plage concernée de-15 à 32 degrés car le modèle risque de ne pas capter des effets non linéaires extrêmes.
Out put du test
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 151.19771 1.17861 128.28 <2e-16 ***
temperature -2.99896 0.06181 -48.52 <2e-16 ***
—
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 10.07 on 98 degrees of freedom
Multiple R-squared: 0.96, Adjusted R-squared: 0.9596
F-statistic: 2354 on 1 and 98 DF, p-value: < 2.2e-16
Réponse 4
1.Test de corrélation
D’abord on définit les variables : On cherche à expliquer ou prédire les ventes (y) par le taux d’inflation (x)
Pour confirmer s’il y a une corrélation négative, on va utiliser soit un test de corrélation avec Rcmdr ou avec la fonction cor.test()
Formuler les hypothèses :
H₀ : ρ = 0 Il n’y a pas de corrélation linéaire entre les ventes (y) et le taux d’inflation (x)
H₁ ρ<0 Il existe une corrélation linéaire négative entre les ventes (y) et le taux d’inflation (x)
Output du test :
Pearson’s product-moment correlation
data: Ex4_vente$ventes and Ex4_vente$inflation
t = -8.0198, df = 98, p-value = 1.151e-12
alternative hypothesis: true correlation is less than 0
95 percent confidence interval:
-1.0000000 -0.5179545
sample estimates:
cor
-0.6294772
Le p-value (≈0) est très inférieur à 0.05, donc on rejette H₀.
Ainsi, il existe, au seuil de 5 %, une corrélation linéaire négative statistiquement significative entre le taux d’inflation et les ventes.
2.Prédiction
Pour déterminer les estimations, on utilise la droite de régression :
y= 200.727 – 6.536 x
et avec la fonction predict à ajouter ce code dans la console si vs utilisez Rcmdr et n’oubliez pas de mettre le nom de votre modèle à la palace de modele4
predict(modele4, newdata = data.frame(inflation= c(3.896, 9.778 )))
1 2
175.263 136.82
Pour trouver les valeurs de ventes réelles dans les données Pour Rcmdr ajouter dans la console:
subset(Ex4_vente, subset=(inflation >= 3.895 & inflation <= 3.897) |
(inflation >= 9.777 & inflation <= 9.779))
Créer un sous -sensemble:
Données→ jeu de données actif→ sous -sensemble→
entrer dans Expression de sélection: (inflation >= 3.895 & inflation <= 3.897) |
(inflation >= 9.777 & inflation <= 9.779))
Mettre un nouveau nom par exp: ds
inflation ventes
<dbl> <dbl>
1 3.90 176.
2 9.78 112.
Mettons toutes les valeurs en tableau pour mieux comparer:
Inflation | Vente estimée | Vente réelle |
3.896 | 175.26 | 175.71 |
9.778 | 136.82 | 112.01 |
Pour un taux relativement bas, l’estimation est proche de la valeur réelle, Par contre, pour un taux proche des extrémités (10%) il y a un écart notable 22% env.(136.82-112.01/112.01) entre les estimations et les valeurs réelles.
Cela montre que le modèle sous-estime l’impact négatif de l’inflation élevée, et n’est pas fiable en dehors d’un certain intervalle.
3. Part de la variabilité des ventes expliquée par l’inflation
C’est le coef. de détermination R2 qui indique la variabilité de y expliquée par x :
Pour ce modèle R2 = 0.39 Cela signifie que 39 % de la variabilité des ventes est expliquée par le taux d’inflation.
Ce niveau est relativement faible, souvent, on considère ≥70 % comme satisfaisant pour des prédictions fiables.
4.Recommandation
Bien que le modèle montre une relation linéaire significative, sa capacité prédictive est limitée :
- R² faible (39 %),
- Erreurs importantes pour des taux d’inflation élevés (voir le graphique ci-dessous)
Il serait pertinent d’examiner les résidus du modèle plus en détail. Cela permettrait de :
Vérifier si les hypothèses de la régression linéaire sont respectées (homoscédasticité, normalité, etc.),
Détecter d’éventuels schémas ou comportements non captés par le modèle (comme une relation non linéaire),
Mieux comprendre les limites du modèle, en particulier pourquoi il échoue à prédire correctement à des niveaux d’inflation élevés.
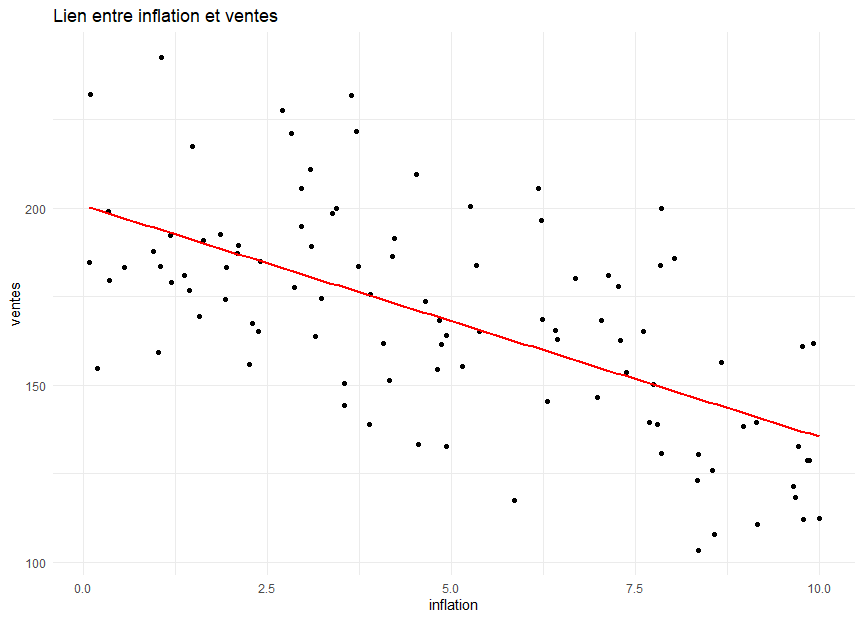
Conclusion :
Nous ne recommandons pas d’utiliser ce modèle pour effectuer des prédictions fiables, surtout en cas de fortes fluctuations de l’inflation. Il serait judicieux d’envisager un modèle plus sophistiqué (non linéaire ou multivarié), ou d’inclure d’autres variables explicatives (revenu des ménages, promotions, saisonnalité, etc.).
Output du test :
Call:
lm(formula = ventes ~ inflation, data = Ex4_vente)
Residuals:
Min 1Q Median 3Q Max
-45.129 -15.818 -2.664 15.125 54.914
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 200.727 4.666 43.02 < 2e-16 ***
inflation -6.536 0.815 -8.02 2.3e-12 ***
—
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 23.83 on 98 degrees of freedom
Multiple R-squared: 0.3962, Adjusted R-squared: 0.3901
F-statistic: 64.32 on 1 and 98 DF, p-value: 2.302e-12